
Article
Your Rate Limiter Is Your Biggest Outage Risk
Why your rate limiter might be your biggest outage risk — and how to fix it with the right algorithms and architecture.
Learn more
Amazon cloud services for IAM, networking, managed Kubernetes, and IaC workflows
AWS dominates the cloud infrastructure market for good reason: its breadth of services lets platform teams assemble opinionated internal platforms without building everything from scratch. EKS for managed Kubernetes, CodePipeline and CodeBuild for CI/CD, CloudFormation and CDK for infrastructure-as-code, and IAM for fine-grained access control form the backbone of most enterprise platform engineering stacks. The ecosystem is deep enough that nearly any operational pattern has a managed-service answer.
Platform engineers working with AWS spend significant time on IAM policy design, VPC networking, and service quotas—the unglamorous connective tissue that determines whether a self-service platform actually works at scale. Getting cross-account access right with Organizations and Control Tower, wiring up PrivateLink endpoints, and tuning autoscaling policies across EKS node groups are where real operational expertise lives.
The tradeoff is complexity. AWS offers multiple ways to accomplish any goal, and choosing between them has long-term consequences for cost, maintainability, and team cognitive load. A well-built AWS platform abstracts that complexity behind golden paths so application teams get the reliability of battle-tested infrastructure without needing to understand every service interaction underneath.
Why your rate limiter might be your biggest outage risk — and how to fix it with the right algorithms and architecture.

Design module interfaces with sensible defaults, clear breaking-change boundaries, and early validation to create modules teams actually want to use.

Three strategies that cut preview environment costs by 60%+ without sacrificing developer experience.

Quality gates that block too aggressively train engineers to bypass them. Here's how to design gates that catch real problems without becoming obstacles.

A playbook for cluster upgrades that minimizes risk through preparation, proper sequencing, and tested rollback procedures.
The boring resource decisions that actually determine your cloud spend on Kubernetes clusters.

Building only what changed with affected-based builds and remote caching that actually speeds up CI.

Lead time, onboarding time, and ticket deflection metrics that show whether your platform reduces friction.
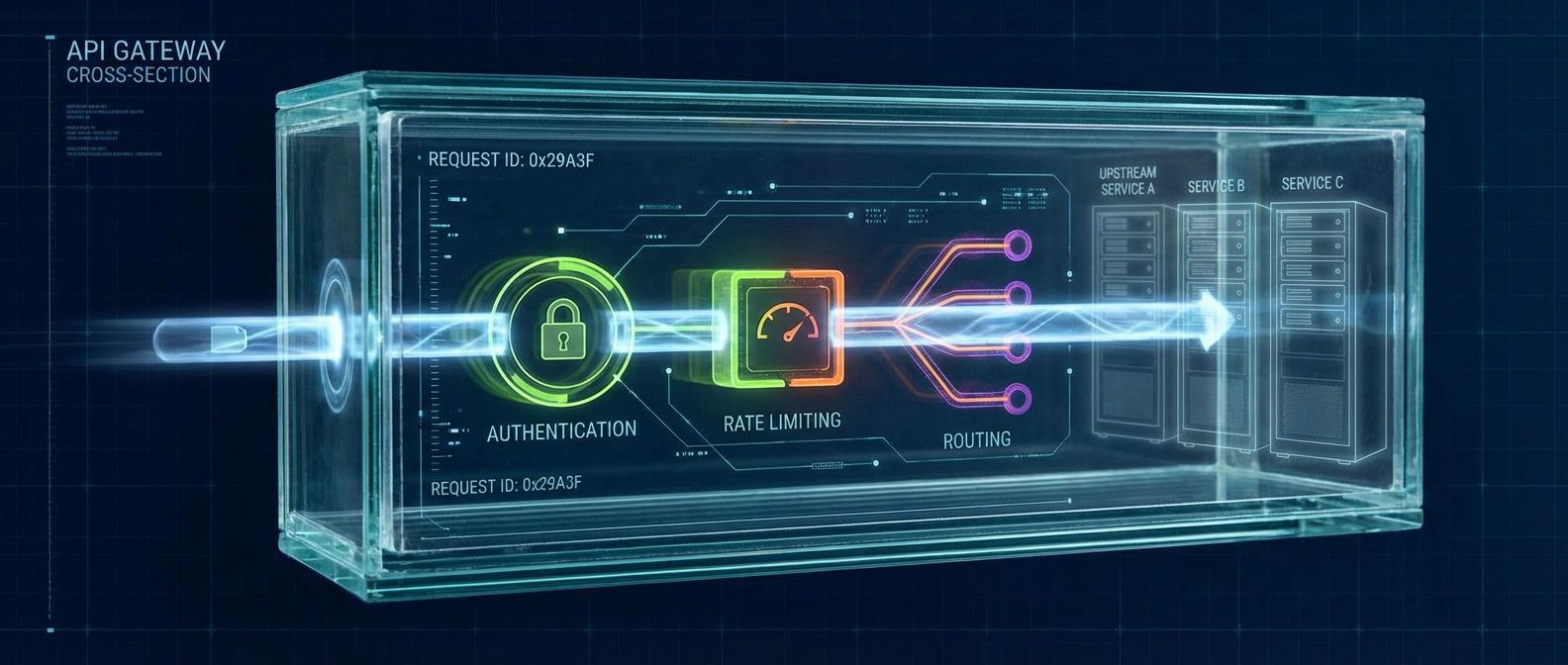
Your gateway dashboards show healthy 200ms latency, but users report 5-second delays. The problem isn't the gateway — it's what you're measuring.

Configuring PodDisruptionBudgets to survive node rotations without blocking cluster operations.

A systematic approach to discovering unknown consumers before you decommission services. Four phases of controlled failure that surface dependencies without causing lasting damage.
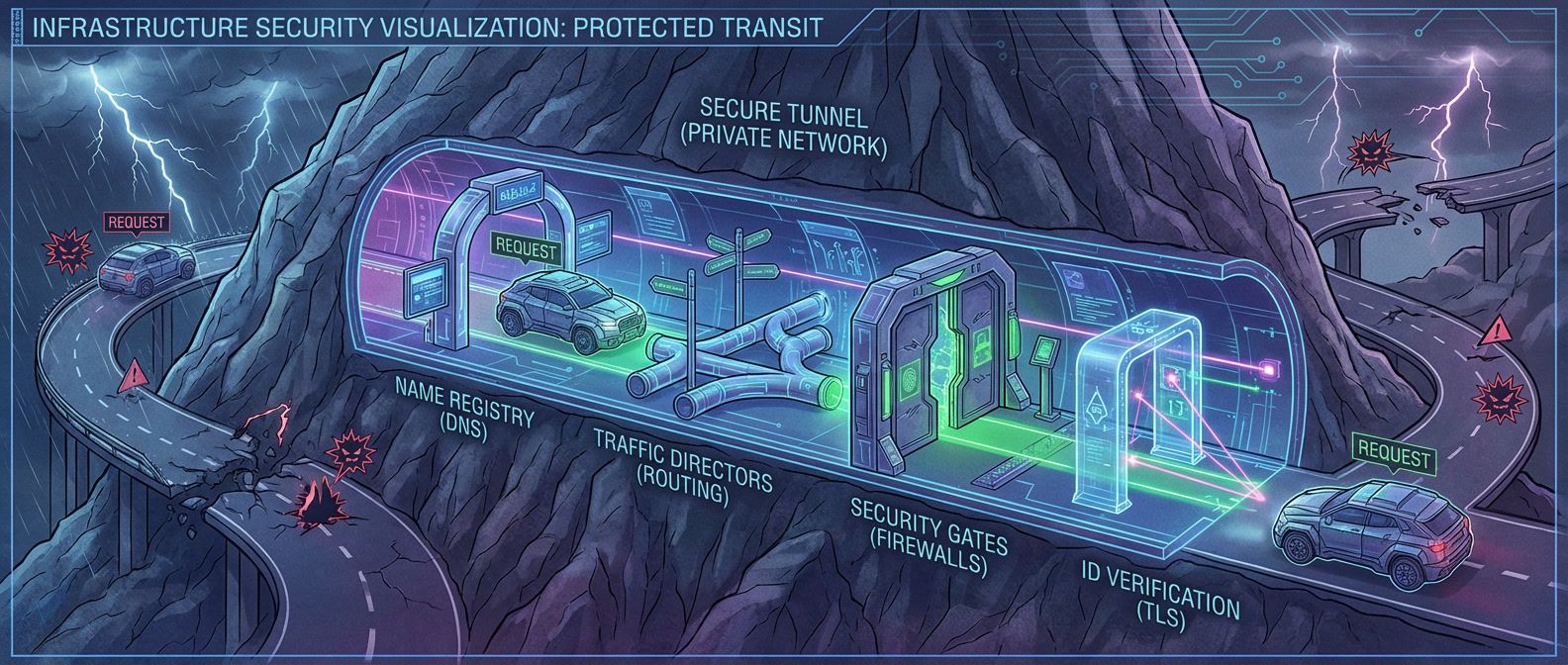
A systematic approach to debugging the networking issues that appear when services move to private connectivity.