Why Moving to Private Networking Broke Everything
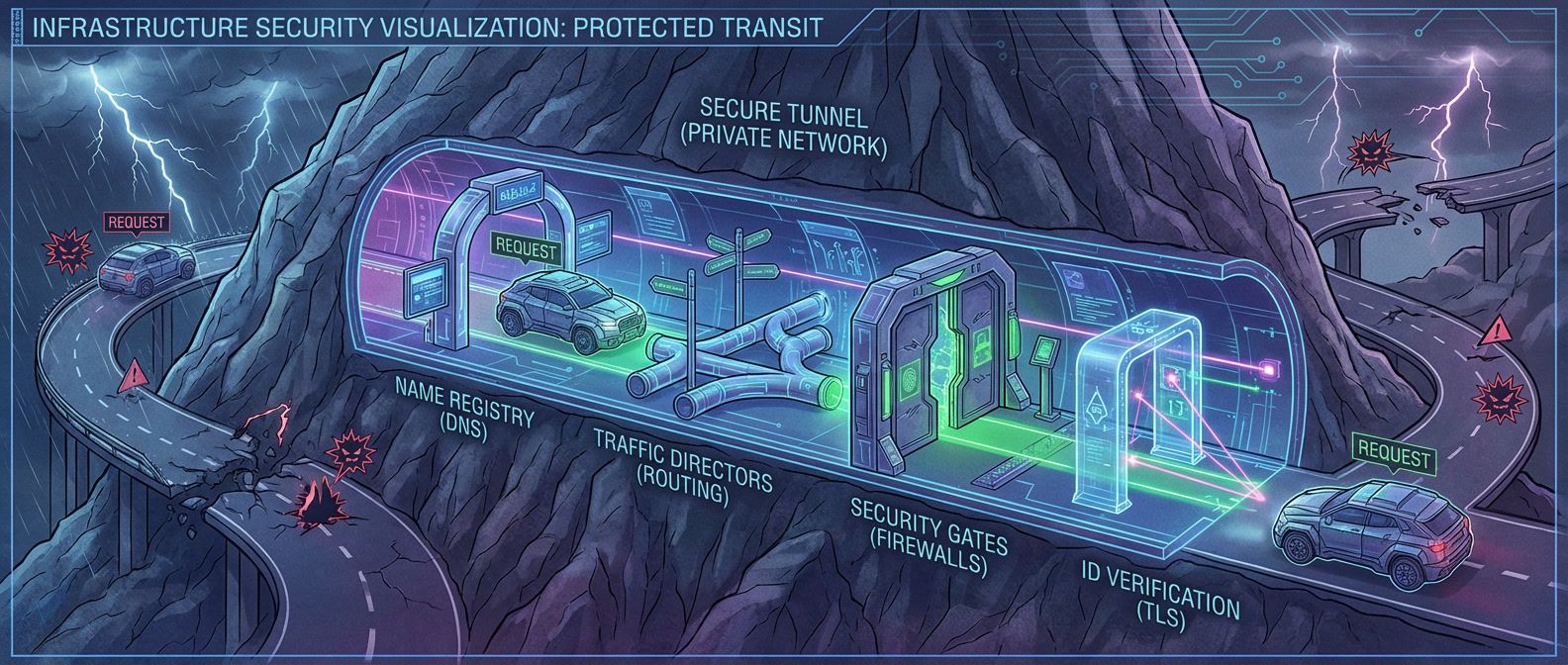
Table of Contents
The migration was supposed to take 30 minutes. We were moving from a publicly-accessible RDS instance to a private endpoint — a straightforward security improvement. The application failed immediately with “connection refused.” We verified the endpoint URL. DNS resolved, but to a different IP than expected. The IP was in a private subnet range, but our VPC couldn’t route to it. We added a route. Now we got “connection reset.” The TLS handshake was failing because the certificate’s SAN didn’t include the private DNS name. We fixed that. Handshake succeeded, but authentication failed — the database saw connections from an unexpected IP because we’d forgotten about NAT.
Three days and four distinct failures later, we had a working connection — and a debugging playbook we’ve used for every migration since.
The Debugging Playbook
Every private networking issue follows the same debugging sequence. Each layer depends on the previous one working correctly — there’s no point checking TLS if packets aren’t reaching the server, and there’s no point checking routing if the name resolves to the wrong IP.
The sequence: DNS → routing → connectivity → TLS → application.
| # | Layer | What to Check | Command | Pass Criteria |
|---|---|---|---|---|
| 1 | DNS | Does the name resolve to the expected private IP? | getent hosts | Returns expected private IP, not public |
| 2 | Routing | Can the kernel find a path to that IP? | ip route get | Shows route via expected interface, no blackhole |
| 3 | Connectivity | Is the port reachable? | nc -zv -w 5 | "Connection succeeded" (not timeout or refused) |
| 4 | TLS | Does the handshake succeed? | openssl s_client -connect | Certificate chain valid, hostname matches SAN |
| 5 | Application | Do credentials and allowlists pass? | Check application logs | Authenticated successfully |
The key insight: failure modes bleed across layers. A timeout could be routing (no path exists), security groups (traffic blocked), or even TLS (some implementations timeout on handshake failure). “Connection refused” could be the service being down, or it could be a firewall actively rejecting the connection. You can’t reliably diagnose by error message alone — you have to verify each layer in order.
For intermittent failures, you may need to iterate through this sequence multiple times, as the failing layer can change between attempts.
DNS: Where Most Failures Start
Cloud VMs don’t use public DNS by default. AWS VPCs get a resolver at the VPC CIDR base address plus two — so 10.0.0.2 for a 10.0.0.0/16 VPC. This resolver handles Route 53 private hosted zones and falls back to public DNS for external names. GCP uses the metadata server at 169.254.169.254, Azure uses 168.63.129.16. If your application is configured to use 8.8.8.8 or another public resolver, it bypasses private DNS entirely.
The most common DNS failure: a private hosted zone exists, the records are correct, but the zone isn’t associated with the VPC where your application runs. Queries return NXDOMAIN even though “the DNS is definitely configured.” I’ve seen this take hours to diagnose because the zone looks fine in the console — you have to check the VPC associations tab specifically.
Split-horizon DNS creates similar confusion. You have a public zone for api.example.com that resolves to a public load balancer, and a private zone for the same name that resolves to an internal endpoint. If the private zone isn’t associated with your VPC, queries fall through to public DNS and return the public IP. Traffic then goes out through NAT, across the internet, and back in — adding latency and potentially failing security group checks.
| Symptom | Likely Cause | Fix |
|---|---|---|
| Resolves to public IP instead of private | Using public DNS or private zone not associated | Configure VPC resolver, associate zone |
| NXDOMAIN for private endpoint | Zone not associated with source VPC | Associate zone with VPC |
| Same name resolves differently in different places | Split-horizon misconfiguration | Verify zone associations across all VPCs |
| Old IP returned after endpoint change | DNS caching with high TTL | Lower TTL before migrations, flush caches |
When debugging DNS, always compare dig @<vpc-resolver> <hostname> with dig @8.8.8.8 <hostname>. If they return different IPs, you’ve found your split-horizon issue.
Routing and Security: The Silent Failures
Once DNS resolves correctly, packets still need a path. Cloud networks don’t tell you when that path doesn’t exist — packets just disappear.
VPC routing follows “most specific route wins.” If you have routes for 0.0.0.0/0 (internet gateway), 10.0.0.0/16 (local VPC), and 10.1.0.0/16 (peered VPC), traffic to 10.1.5.100 takes the peering route. But if someone deletes the peering connection without removing the route, you get a blackhole — the route exists but leads nowhere.
I hit this exact scenario during a VPC consolidation project. We decommissioned a peered VPC but left the routes in place. For three weeks, everything worked because nothing was trying to reach that CIDR. Then a new service deployed with a dependency on an endpoint that had moved. Timeout. No error message, no ICMP unreachable — just packets vanishing into a route that pointed at a deleted peering connection.
The silent failure problem makes routing issues particularly frustrating. Traditional networks return ICMP “destination unreachable” when routing fails. Cloud networks often don’t. A timeout could mean no route exists, or it could mean a security group is blocking traffic, or the target service is down. They all look identical from the client side.
Security groups and NACLs both filter traffic, but they trip people up in different ways.
Security groups are stateful — you allow inbound on port 443, and return traffic is automatically permitted. They operate at the instance level (technically the ENI), and you can only define allow rules.
NACLs are stateless — you must explicitly allow both inbound traffic and the return traffic on ephemeral ports (1024-65535). They operate at the subnet level, rules are evaluated in order, and you can define both allow and deny.
The classic NACL mistake: you allow outbound traffic to a database on port 5432, but forget to allow inbound on ephemeral ports for the response. Connection times out, and you spend an hour checking security groups because “stateful” makes more intuitive sense.
One more gotcha: NAT changes source IPs. If your application connects through a NAT gateway, the destination sees the NAT gateway’s IP, not your instance’s IP. Security group rules allowing the instance’s IP won’t match. And if you’re using security group references (allowing traffic from “sg-abc123” instead of a CIDR), those don’t work across VPC peering or transit gateway — you have to use CIDR blocks instead.
Cloud networks often don’t return ICMP unreachable for routing failures — packets just disappear. A timeout doesn’t mean “firewall blocked”; it might mean “no route exists.” Always verify routing with ip route get before assuming security group issues.
What’s Next
This debugging sequence — DNS, routing, connectivity, TLS, application — handles most private networking failures you’ll encounter. But some scenarios require deeper knowledge: TLS certificate management with private CAs (including the trust store configurations that trip up every language differently), cross-VPC connectivity patterns and their tradeoffs (when peering breaks down vs. when transit gateway adds unnecessary complexity), and the specific failure modes of private endpoint migrations.
Private Networking: DNS, Routing, and TLS Failures
Debugging the networking issues that appear when services move to private connectivity.
What you'll get:
- Private DNS verification checklist
- Routing and NACL debug flow
- TLS handshake troubleshooting guide
- Endpoint migration preflight template

The teams that handle private networking well aren’t the ones with the fanciest tools. They’re the ones who’ve internalized this playbook before the first production incident. When something breaks at 3am, you don’t want to be guessing which layer failed.
Share this article
Enjoyed the read? Share it with your network.




