Stop Alerting on CPU: What to Monitor Instead

Table of Contents
Your on-call engineer gets paged at 2 AM for high CPU on a batch processing node. They investigate for 20 minutes, find nothing wrong, and go back to sleep. An hour later, another page: disk space on a log aggregator. Another false alarm. By the time the third alert fires — this one signaling elevated API error rates — they’ve learned to assume it’s another false positive. They check Slack, see nothing, and go back to sleep.
In the morning, they discover the payment service was down for 45 minutes. Customers couldn’t complete purchases. The alert was real; the engineer had just been trained to ignore it.
This is alert fatigue in action.
The Symptom vs Cause Distinction
The most common alerting mistake is alerting on causes rather than symptoms. High CPU, low disk space, elevated connection counts — these are causes. They might affect users, or they might not. Request latency, error rates, failed transactions — these are symptoms. They tell you users are actually experiencing problems right now.
Consider three classic cause-based alerts and their symptom-based alternatives:
- 1 High CPU usageFires when cpu_usage > 90%. But CPU can spike during legitimate load, garbage collection, or batch jobs without any user impact. The symptom-based alternative-elevated request latency-only fires when users are actually affected. Many different causes lead to latency; one symptom alert catches them all.
- 2 Low disk spaceFires when disk_free < 10%. But this triggers on expected growth, archival systems, and cold storage that's supposed to be full. The symptom-based alternative-write failures increasing-only fires when disk space is causing actual failures. Keep disk space as a ticket for business hours, not a 2 AM page.
- 3 Database connections highFires when connections exceed 80% of max. But connection pools often run hot without issues. The symptom-based alternative-query timeouts-only fires when connection exhaustion impacts queries. Connection monitoring becomes a dashboard metric, not an alert.
The pattern is consistent: causes are potential problems; symptoms are actual problems. This leads to a simple rule: page on symptoms, ticket on causes. text: ‘If you can’t write down how to diagnose and remediate an alert, you don’t understand it well enough to wake someone up for it. The runbook doesn’t need to be exhaustive-a summary of user impact, links to relevant dashboards, common causes ranked by likelihood, and escalation criteria are enough. The point is that a 2 AM responder shouldn’t have to reverse-engineer what the alert means.’, This creates a natural hierarchy for categorizing alerts:
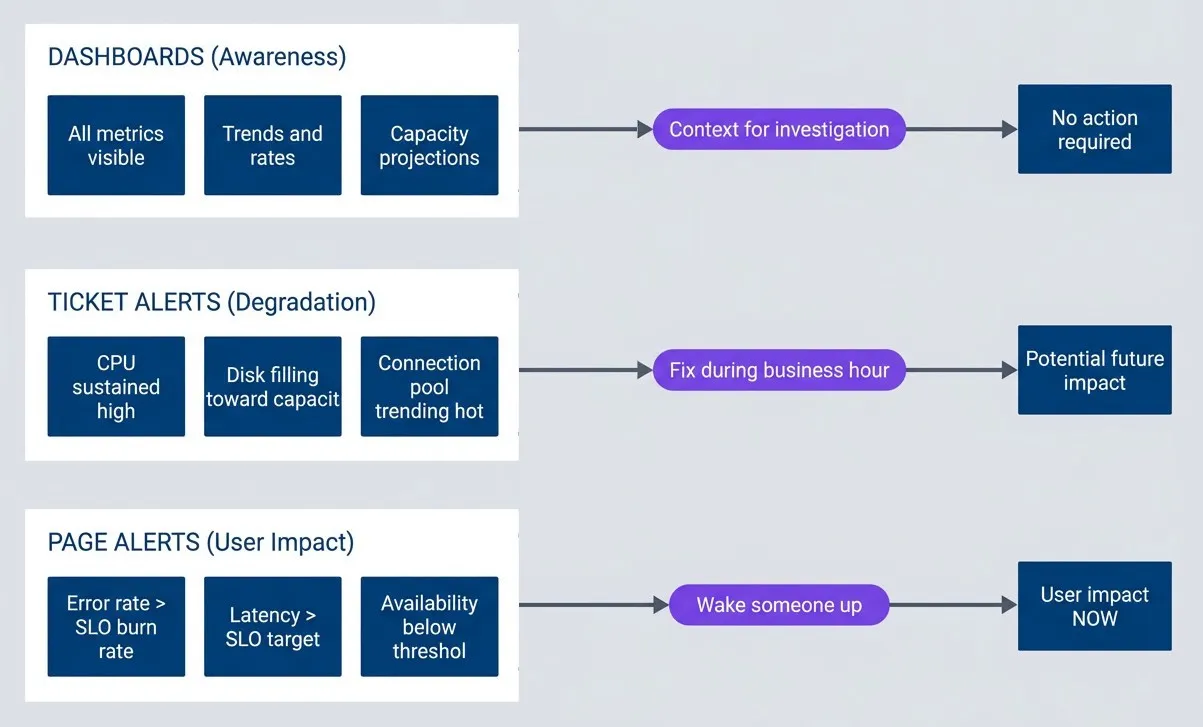
The alerting pyramid.
description
Top-to-bottom flowchart divided into three grouped tiers. The top tier, Page Alerts User Impact, contains Error rate greater than SLO burn rate, Latency greater than SLO target, and Availability below threshold. This tier points to User impact NOW with the label Wake someone up. The middle tier, Ticket Alerts Degradation, contains CPU sustained high, Disk filling toward capacity, and Connection pool trending hot. This tier points to Potential future impact with the label Fix during business hours. The bottom tier, Dashboards Awareness, contains All metrics visible, Trends and rates, and Capacity projections. This tier points to No action required with the label Context for investigation. The diagram shows a hierarchy where user-facing symptoms warrant urgent pages, potential causes become tickets, and the rest of the operational data stays on dashboards for context.
SLO-Based Burn Rate Alerting
Symptom-based alerting answers what to alert on. Burn rates answer when.
The problem with raw thresholds is they lack context. A 1% error rate sounds scary, but is it? If your SLO allows 0.1% errors over a month, that 1% rate means you’re burning through your error budget 10x faster than sustainable. You have about 3 days before you exhaust your monthly budget. Urgent, but not a 2 AM emergency.
Burn rate measures how fast you’re consuming your error budget relative to a sustainable pace. A 1x burn rate means you’ll exactly exhaust your budget by month’s end — sustainable but leaves no margin. A 14.4x burn rate means you’ll exhaust your entire monthly budget in just 2 hours. That’s an emergency.
The math: if your monthly budget is 0.1% errors and you’re currently seeing 1.44% errors (14.4 × 0.1%), you’re burning 14.4x faster than sustainable. At that rate, your 30-day budget disappears in 30 days ÷ 14.4 ≈ 2 hours.
| Burn Rate | Budget Exhaustion | Appropriate Response |
|---|---|---|
| 14.4x | 2 hours | Page immediately |
| 6x | 5 hours | Page during waking hours |
| 3x | 10 days | Create ticket |
| 1x | 30 days | Dashboard metric only |
Here’s what a 14.4x burn rate alert looks like in Prometheus:
groups:
- name: slo-burn-rate-alerts
rules:
- alert: APIAvailabilityFastBurn
expr: |
(
sum(rate(http_requests_total{status=~"5.."}[5m]))
/ sum(rate(http_requests_total[5m]))
) > (14.4 * 0.001)
for: 2m
labels:
severity: critical
annotations:
summary: "API error rate burning SLO budget rapidly"
runbook_url: "https://runbooks.example.com/api-availability"One refinement makes burn rate alerts even more reliable: multi-window alerting. Single-window alerts have a problem — short windows catch spikes but also false-positive on brief blips; long windows miss fast-moving incidents. The solution is requiring both a short and long window to breach before alerting.
For example, a 14.4x burn rate alert might require both conditions to be true: the 5-minute error rate exceeds the threshold and the 1-hour error rate exceeds the threshold. If a 30-second traffic spike pushes errors to 2% but the hourly rate is still 0.05%, the alert doesn’t fire — the spike isn’t sustained. Conversely, if an incident resolved 20 minutes ago, the 1-hour window might still show elevated errors, but the 5-minute window is clean — no alert, because the problem is already over.
Sustaining Alert Quality
The symptom vs cause distinction and burn rate math are the technical foundation, but sustainable alerting requires organizational practices too.
Alert Fatigue: Symptom-Based Alerting That Works
Designing alerts that wake people up for real problems and include runbooks for resolution.
What you'll get:
- Symptom alert design checklist
- Burn rate threshold calculator
- Runbook template starter pack
- Monthly alert hygiene rubric

- Every alert needs a runbook. If you can't write down how to diagnose and remediate an alert, you don't understand it well enough to wake someone up for it. The runbook doesn't need to be exhaustive-a summary of user impact, links to relevant dashboards, common causes ranked by likelihood, and escalation criteria are enough. The point is that a 2 AM responder shouldn't have to reverse-engineer what the alert means.
- Track your actionable rate. If fewer than 80% of your alerts require human intervention to resolve, you have a noise problem. An alert that auto-recovers, requires no action, or fires for non-issues is training your team to ignore the pager. Track this metric weekly and treat declining actionable rates as a priority issue.
- Review alerts monthly. Alerts decay. Thresholds that made sense six months ago may be too sensitive or too lax today. Services get renamed. Runbooks reference deprecated tools. Schedule a monthly review where you walk through every alert that fired, ask whether it was actionable, and decide whether to keep, modify, or delete it. Retire any alert that hasn't fired in 6 months or has less than 50% actionable rate.
The goal isn’t zero alerts — it’s ensuring every alert that fires represents a real problem that requires human intervention, and the human receiving it has everything they need to resolve it quickly. Start by auditing your current alerts: calculate your actionable rate over the past month. If it’s below 80%, you have work to do.
Alert fatigue isn’t a discipline problem you can train your way out of. It’s a design problem you can engineer your way out of. Page on symptoms, ticket on causes, and let burn rates determine urgency.
Share this article
Enjoyed the read? Share it with your network.




