Why Your Kubernetes Secrets Strategy Will Fail at 3 AM
Table of Contents
It’s 3 AM and Vault is down. Your on-call engineer gets paged because deployments are failing — pods stuck in ContainerCreating, blocking a critical hotfix. Meanwhile, another team’s services keep humming along despite the same outage. The difference isn’t luck. It’s how secrets get into pods.
Both teams use Vault. Both followed the documentation. But one team chose External Secrets Operator, which syncs secrets periodically and caches them as native Kubernetes secrets. The other chose the Secrets Store CSI Driver, which fetches secrets on-demand when pods start. When Vault went down, ESO‘s cached secrets kept working. CSI‘s synchronous fetches failed, and pods couldn’t start. This isn’t about which tool is better — it’s about understanding the failure mode you’ve chosen before it matters.
The Two Patterns That Matter
Both work fine when your secret manager is healthy. The difference is what happens when it isn’t. ESO decouples secret fetching from pod lifecycle — the controller syncs independently, and pods consume cached Kubernetes Secrets. CSI couples them tightly — pods can’t start until secrets are fetched. This architectural difference determines everything about how your applications behave during an outage.
| Pattern | Existing Pods | New Pods | Recovery |
|---|---|---|---|
| ESO | ✅ Running | ✅ Start (cached) | Automatic |
| CSI Driver | ✅ Running | ❌ Blocked | May need intervention |
Init containers offer a third path — DIY scripts that fetch secrets before your main container starts — but they require you to implement retry logic, fallback sources, and monitoring yourself. For most organizations, ESO or CSI covers the use case without that operational burden. (We cover init container patterns with fallback logic in our full guide.)
ESO: Graceful Degradation
External Secrets Operator works by watching ExternalSecret custom resources in your cluster. When you create an ExternalSecret, the controller fetches the referenced secrets from your external manager and creates (or updates) a native Kubernetes Secret. Your pods consume that Secret normally — via environment variables or volume mounts — completely unaware that it originated from Vault.
The controller runs its reconciliation loop on a configurable interval (typically 15-30 minutes). Each cycle, it checks whether the external secret has changed and updates the Kubernetes Secret if needed. This decoupling is ESO‘s key advantage: the Kubernetes Secret persists in etcd independent of the external manager’s availability.
When Vault goes down, ESO‘s controller logs errors and keeps retrying. But the Kubernetes Secret it already created remains unchanged. Existing pods keep running with their last-synced values. Here’s the part that surprises people: new pods can also start. They mount the Kubernetes Secret normally, unaware that ESO is failing to sync. The Secret itself is the cache.
The downside is silent staleness. If you rotate a database password in Vault but ESO can’t sync for two hours, your pods run with the old password. They work fine — until something restarts them after the old password has been revoked. This is why monitoring sync status matters. An ExternalSecret that hasn’t synced in multiple refresh intervals indicates a problem, even if your applications seem healthy.
The cached Secret is encrypted in etcd only if you’ve configured encryption at rest on your cluster. The external manager’s encryption doesn’t carry over — once ESO syncs a secret into Kubernetes, it’s subject to your cluster’s encryption configuration.
For most workloads — web applications, APIs, microservices—15-30 minutes of staleness is acceptable. Connection pools cache connections anyway, so this staleness window rarely causes immediate failures. ESO‘s graceful degradation keeps services running through outages, which is usually the right tradeoff.
CSI Driver: Loud Failures
The Secrets Store CSI Driver takes the opposite approach. Instead of syncing secrets to Kubernetes Secret objects, it mounts them directly into pods as volumes. When a pod starts, the CSI driver intercepts the volume mount, authenticates to Vault using the pod’s service account, fetches the secrets, and presents them as files in the container’s filesystem.
The pod cannot start until this volume mount succeeds. If Vault is unavailable, the mount fails. The pod stays in ContainerCreating with events showing MountVolume.SetUp failed. No graceful degradation — no start.
This has cascading implications that aren’t obvious until you experience them:
- New deployments block entirely — no pods can start
- In-progress rolling updates stall because replacement pods can't become ready
- Horizontal pod autoscaler scales up pods that immediately get stuck
- A node reboot during an incident restarts pods that can't fetch their secrets
Existing pods continue running — they already have their secrets mounted. But anything that needs to start fresh is blocked until Vault recovers.
This failure mode is loud, which is actually its advantage for certain use cases. Payment processing systems might prefer failing visibly over running with potentially stale credentials. Compliance requirements sometimes prohibit caching secrets in Kubernetes at all. If you need to guarantee that every pod startup uses fresh credentials from the authoritative source, CSI‘s blocking behavior is a feature, not a bug.
CSI‘s failure mode can cascade quickly during incidents. A Vault outage combined with a node failure means pods that were running fine suddenly can’t restart. Plan for this with pre-deployment health checks or consider combining CSI with a fallback Kubernetes Secret.
Choosing Your Failure Mode
The decision between ESO and CSI comes down to two questions: Can your application tolerate minutes of staleness? And can your operations tolerate blocked deployments during secret manager outages?
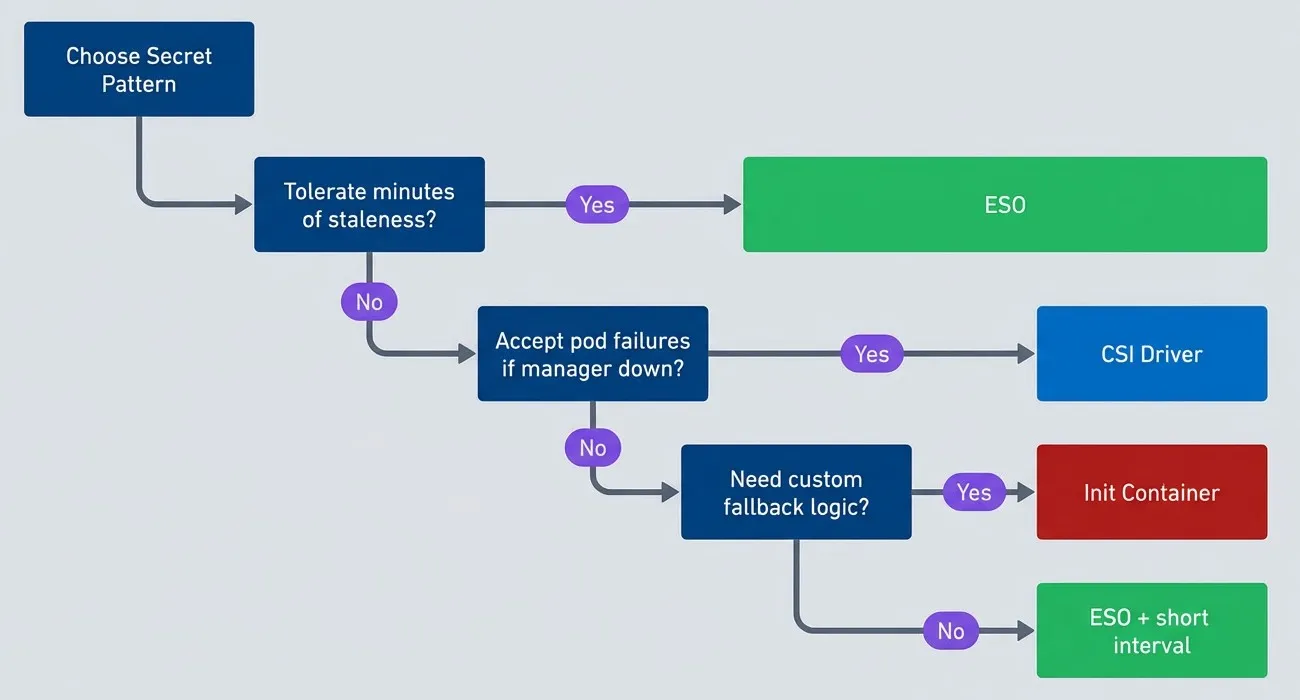
Pattern decision tree.
description
Flowchart guiding the choice between Kubernetes secret injection patterns based on failure tolerance. The process starts at Choose Secret Pattern and asks whether the application can tolerate minutes of staleness. If yes, the recommendation is ESO. If no, the chart asks whether the team accepts pod failures when the secret manager is down. If yes, the recommendation is CSI Driver. If no, the chart asks whether custom fallback logic is needed. If yes, the recommendation is Init Container. If no, the recommendation is ESO plus a short refresh interval. The diagram highlights that the main decision criteria are tolerance for stale secrets, tolerance for blocked pod startup during secret-manager outages, and whether the team is willing to build custom fallback behavior.
The diagram includes init containers as an option for custom fallback logic — useful when you need behavior that ESO and CSI don’t provide out of the box. Our full guide covers implementation patterns including multi-source fallbacks and sidecar refresh.
For most organizations, ESO is the right default. It’s operationally simpler, GitOps-friendly (ExternalSecrets are declarative resources you commit to version control), and its failure mode keeps services running. Reserve CSI for specific applications with strict compliance requirements or real-time credential needs.
Kubernetes Secrets: ESO vs CSI vs Init Containers
Comparing secret injection patterns and their failure modes when connecting Vault or cloud secret managers.
What you'll get:
- Secret pattern comparison matrix
- ESO configuration starter templates
- CSI failure mode runbooks
- Rotation and audit checklist

The mistake isn’t choosing either pattern. It’s not understanding which failure mode you’ve chosen. The team that slept through the 3 AM Vault outage didn’t get lucky — they understood that ESO‘s cached secrets would keep their services running. The team that got paged made a valid choice too; for their payment system, blocking on fresh credentials was the right call. Their runbooks reflected it.
Start with ESO for the majority of workloads, with a 15-minute refresh interval, and monitor sync status with alerts on stale ExternalSecrets. Add CSI for specific high-security applications where staleness is unacceptable. This gives you operational simplicity with escape hatches for edge cases.
Whatever you choose, document it. When the next outage happens, your incident responders shouldn’t be learning your secret injection architecture for the first time.
Share this article
Enjoyed the read? Share it with your network.




