
Article
Terraform Module Defaults That Won't Break Your Consumers
Design module interfaces with sensible defaults, clear breaking-change boundaries, and early validation to create modules teams actually want to use.
Learn more

Cluster operations, container orchestration, IaC, and running workloads at scale
Cloud infrastructure is where abstractions meet reality. Kubernetes promises declarative workload management, but delivering on that promise requires understanding scheduling semantics, networking quirks, and the failure modes that emerge when you actually run production traffic. This category covers the operational side of cloud-native infrastructure: container orchestration, multi-cluster patterns, infrastructure-as-code tooling, and the cloud provider specifics that documentation glosses over.
The focus is practical. Requests and limits sound straightforward until a misconfigured QoS class causes cascading evictions during a traffic spike. Terraform state management is simple until your team discovers locking race conditions during a rollback. Helm releases work fine until drift accumulates across dozens of services and nobody knows what is actually deployed. These articles address the gaps between documentation and production.
Whether you are sizing pods with incomplete metrics, debugging DNS latency in a cluster, planning a Kubernetes upgrade that will not wake anyone up, or trying to understand why your cloud bill keeps climbing, the content here draws from hands-on experience with the unglamorous work of keeping infrastructure reliable.
Design module interfaces with sensible defaults, clear breaking-change boundaries, and early validation to create modules teams actually want to use.

Three strategies that cut preview environment costs by 60%+ without sacrificing developer experience.

A playbook for cluster upgrades that minimizes risk through preparation, proper sequencing, and tested rollback procedures.
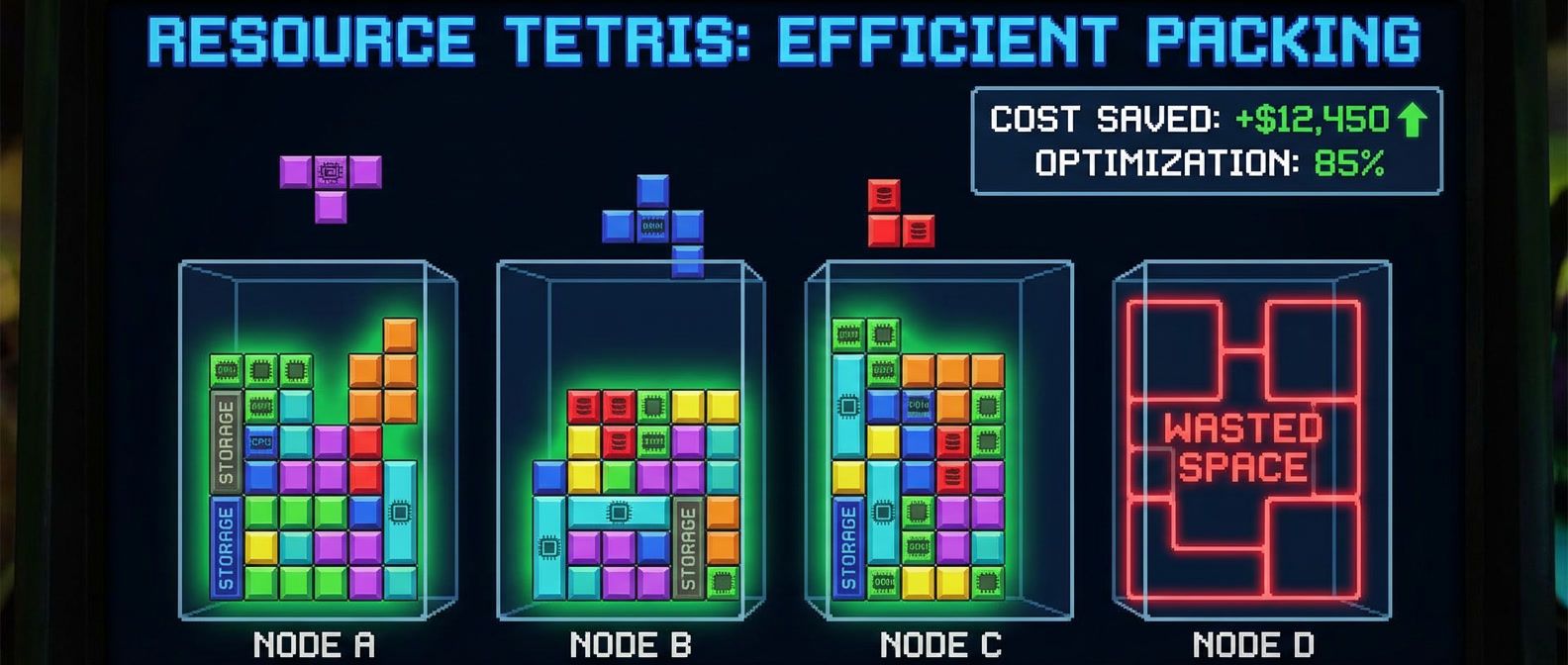
The boring resource decisions that actually determine your cloud spend on Kubernetes clusters.

How to choose between ArgoCD ApplicationSets and Flux for multi-cluster Kubernetes, plus practical drift detection strategies.

Why Horizontal Pod Autoscaler often reacts too slowly and how to tune it for your traffic patterns.

Configuring PodDisruptionBudgets to survive node rotations without blocking cluster operations.
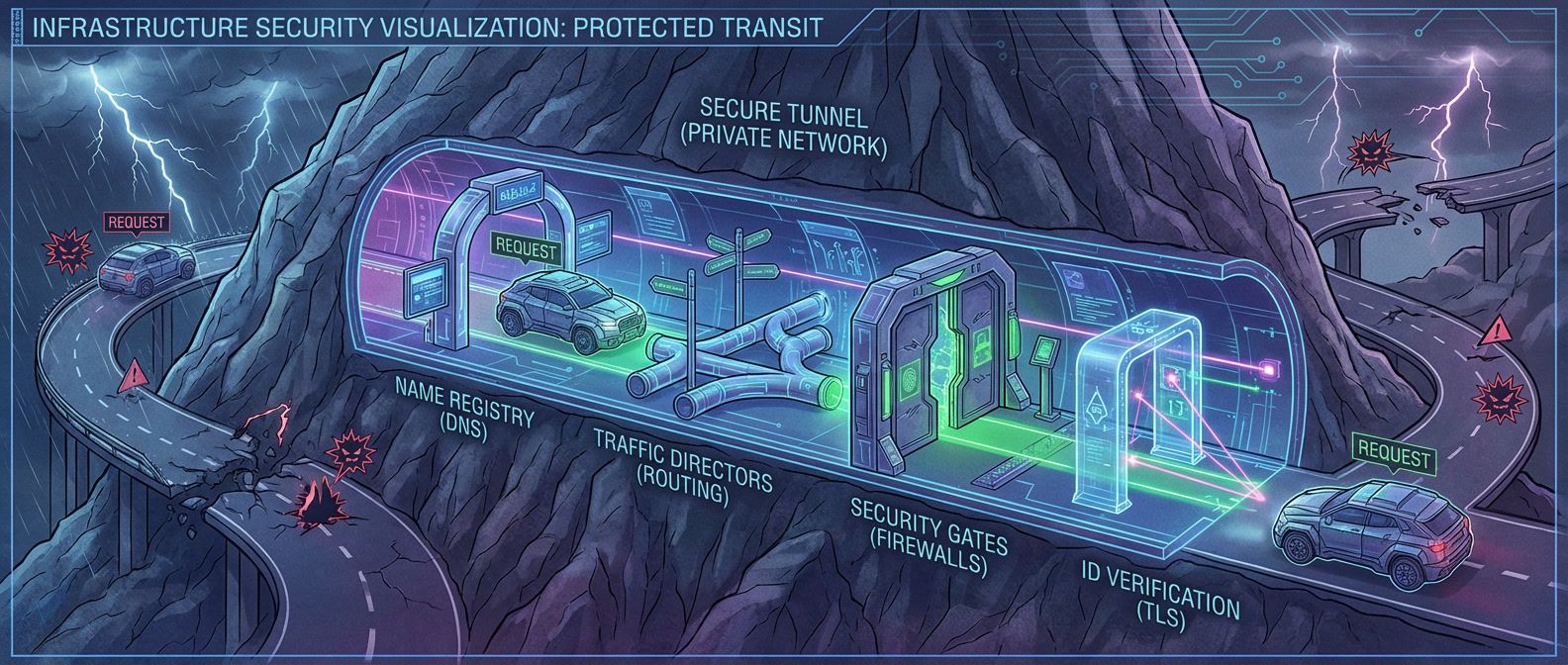
A systematic approach to debugging the networking issues that appear when services move to private connectivity.

The ndots setting causes most external DNS latency in Kubernetes. Learn how to diagnose and fix it in under a minute.

When to use Kubernetes Ingress, when to migrate to Gateway API, and the tradeoffs between them.

Long-lived service account keys are the most common - and most preventable - cloud security vulnerability. Workload identity federation replaces static credentials with cryptographic proof of identity, eliminating an entire category of risk.

Implementing infrastructure policies with OPA and Conftest that catch violations before they reach production — starting with pre-commit hooks that run in under two seconds.