Why mTLS Breaks at 3 AM (And How to Fix It)

Table of Contents
A team enables Istio mTLS across their 50-service mesh. Initial rollout goes smoothly. Everyone celebrates the “zero-trust network.” Three months later, at 2:47 AM, all inter-service communication fails simultaneously. The intermediate CA certificate expired. No one knew it had a 90-day TTL — it was the default, and nobody thought to check.
Recovery takes four hours because the on-call engineer has never manually rotated Istio certificates and the runbook doesn’t exist yet.
If this sounds familiar, you’re not alone.
The Operational Reality of mTLS
Standard TLS — what you use when visiting any HTTPS website — is a one-way trust relationship. The server proves its identity to the client by presenting a certificate. The client validates that certificate against its trust store. The server has no idea who the client is at the transport layer.
Mutual TLS adds a second handshake step: after the client validates the server’s certificate, the server requests and validates a certificate from the client. Both parties cryptographically prove their identity before any application data flows.
The operational cost difference is significant. With standard TLS, you manage certificates for servers — maybe dozens or hundreds. With mTLS, every service needs a certificate, and every service needs to validate certificates from every other service it communicates with. In a 100-service mesh, that’s potentially thousands of certificate validation paths to maintain.
| Aspect | Standard TLS | Mutual TLS |
|---|---|---|
| Trust direction | Client trusts server | Bidirectional |
| Certificates needed | Servers only | Every service |
| Identity verification | Server only | Both parties |
| Operational complexity | Low | High |
The mTLS system has multiple certificate layers (workload, issuing CA, intermediate CA, root CA), each with different TTLs. An outage can originate at any layer. Most teams monitor workload certificates but forget about the CAs that sign them.
Certificate Lifecycle — Where Teams Fail
Certificate rotation is where mTLS complexity becomes real. The challenge: replace a certificate that’s actively being used for authentication without breaking any connections.
Workload vs. CA Rotation
For workload certificate rotation, the strategy is straightforward — overlapping validity. Issue the new certificate before the old one expires. Both are valid during the overlap window, so it doesn’t matter which one a service presents. The old certificate eventually expires, and the new one takes over. Service meshes do this automatically.
CA rotation is harder. When you rotate an intermediate or root CA, you’re changing the trust anchor that validates certificates. If you issue certificates from a new CA before services trust that CA, mTLS fails immediately.
The safe order for CA rotation:
- Add the new CA to all trust bundles (services now trust both old and new)
- Verify all services have received the updated trust bundle
- Start issuing certificates from the new CA
- Wait for all workload certificates to rotate to the new CA
- Remove the old CA from trust bundles
This sequence diagram shows the rotation flow:
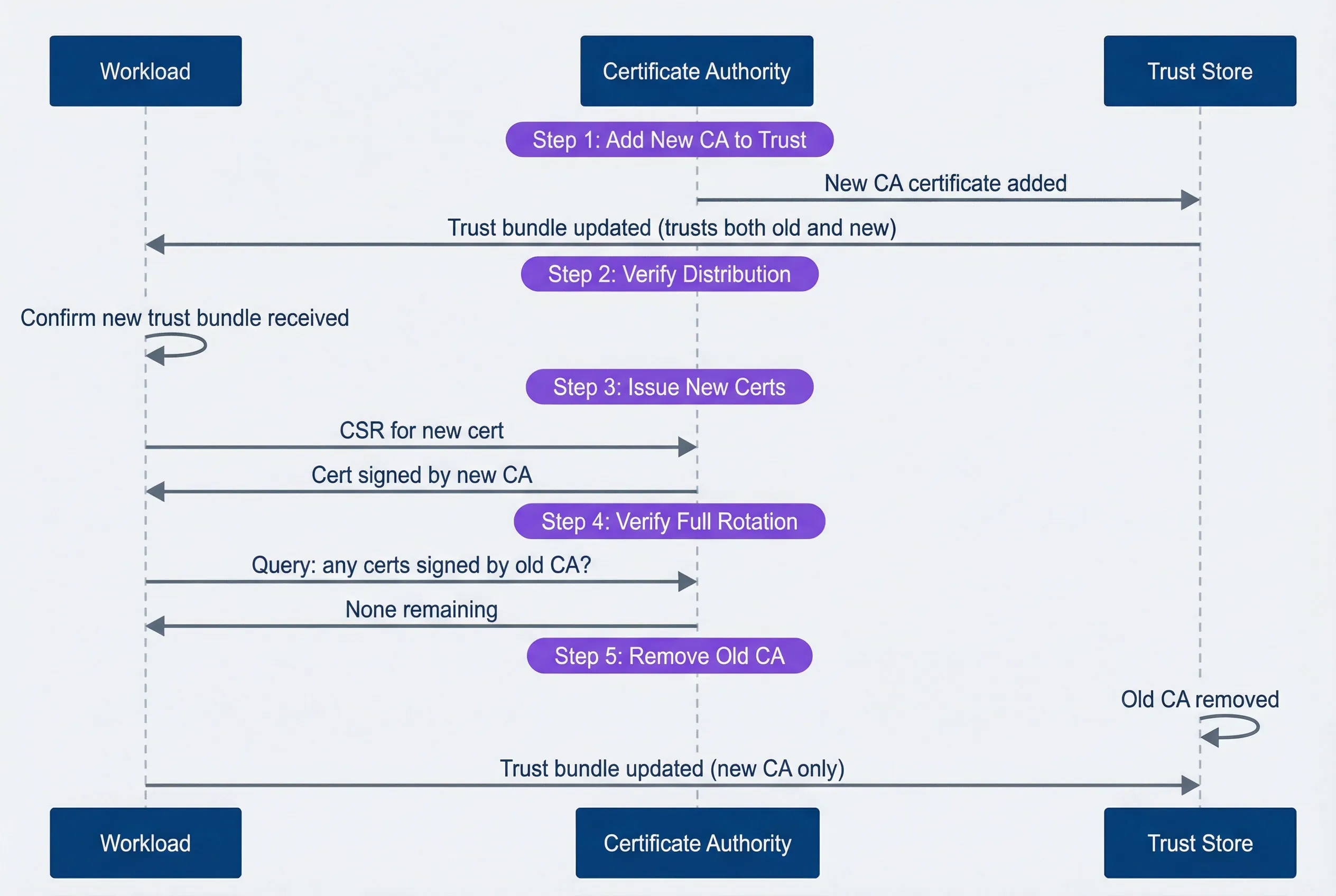
CA rotation sequence showing the safe order of operations.
description
Sequence diagram with three participants: Workload, Certificate Authority, and Trust Store. The first phase is Step 1, Add New CA to Trust. The Certificate Authority sends a new CA certificate to the Trust Store, and the Trust Store updates the Workload with a trust bundle that includes both the old and new CA. The second phase is Step 2, Verify Distribution, where the Workload confirms it has received the new trust bundle. The third phase is Step 3, Issue New Certs, where the Workload sends a CSR for a new certificate to the Certificate Authority, and the Certificate Authority returns a certificate signed by the new CA. The fourth phase is Step 4, Verify Full Rotation, where the Workload asks the Certificate Authority whether any certificates signed by the old CA remain, and the response is that none remain. The fifth phase is Step 5, Remove Old CA, where the Trust Store removes the old CA and the Workload receives an updated trust bundle containing only the new CA. The diagram emphasizes that trust must be updated before new certificates are issued, and the old CA must only be removed after all workloads have rotated.
The cardinal rule of CA rotation: add the new CA to trust stores BEFORE issuing certificates with it. Violating this order causes immediate mTLS failures — services with the old trust bundle will reject certificates signed by the new CA as “unknown authority.”
Expiration Monitoring
Automated rotation should handle expiration seamlessly. But “should” isn’t “will.” Rotation can fail silently — a misconfigured issuer, a network partition, a crashed controller. You need monitoring to catch these failures before they become outages.
For Istio workloads, the istio_agent_cert_expiry_seconds metric exposes time until certificate expiration. For cert-manager, certmanager_certificate_expiration_timestamp_seconds provides the expiration timestamp.
# Prometheus alerting rules for certificate expiration
groups:
- name: certificate-expiration
rules:
- alert: CertificateExpiringSoon
expr: |
(certmanager_certificate_expiration_timestamp_seconds - time()) < 86400
for: 10m
labels:
severity: warning
annotations:
summary: "Certificate {{ $labels.name }} expiring in < 24 hours"
- alert: IstioCertRotationStalled
expr: |
istio_agent_cert_expiry_seconds < 3600
for: 5m
labels:
severity: critical
annotations:
summary: "Workload certificate not rotating - expires in < 1 hour"Different certificate levels need different alert thresholds:
| # | Certificate Type | Typical TTL | Warning | Critical |
|---|---|---|---|---|
| 1 | Workload | 24 hours | 4 hours | 1 hour |
| 2 | Issuing CA | 1 year | 30 days | 7 days |
| 3 | Intermediate CA | 5 years | 6 months | 30 days |
| 4 | Root CA | 20 years | 2 years | 6 months |
The CA that expires is rarely the one you’re watching. Set alerts at every level of the hierarchy.
Debugging When Things Go Wrong
mTLS failures produce cryptic errors. The TLS handshake fails, and you get a generic “connection reset” or “certificate verify failed” with minimal context. Knowing the common failure modes helps narrow down the problem quickly.
Common Failure Modes
- Certificate expired The most common cause of mTLS outages. Error messages include x509: certificate has expired. Check expiration with openssl x509 -enddate -noout -in cert.pem. Fix by forcing rotation or restarting the workload to trigger certificate renewal.
- Trust chain broken The certificate is valid but the CA that signed it isn't in the trust store. You'll see x509: certificate signed by unknown authority. This happens during CA rotation if trust bundles aren't updated before new certificates are issued.
- SAN mismatch The certificate is valid but doesn't include the hostname being used. Error: x509: certificate is valid for X, not Y. This commonly happens when DNS names change or when certificates are issued with incomplete SAN lists.
- Wrong key usage The certificate exists but wasn't issued for mTLS. If it only has serverAuth in Extended Key Usage, it can't be used as a client certificate. Reissue with both serverAuth and clientAuth.
I once spent two hours debugging a “connection reset by peer” that turned out to be a certificate with serverAuth only — no clientAuth. The error message mentioned nothing about key usage. The fix was a one-line change to the certificate spec, but finding it required systematically ruling out every other possibility.
| Symptom | Likely Cause | First Check |
|---|---|---|
| Connection refused | Service not listening | `netstat -tlnp` |
| Connection reset | TLS version mismatch or expired cert | `openssl x509 -enddate` |
| "Unknown authority" | Trust bundle missing CA | `openssl verify -CAfile` |
| "Valid for X, not Y" | SAN mismatch | Check certificate SANs |
| Intermittent failures | Rotation in progress | Check rotation timing |
The Diagnostic Toolkit
When mTLS fails in an Istio environment, these commands help narrow down the problem. First, identify the affected pod — check your alerting system or look for pods with restart loops using kubectl get pods | grep -E '(Error|CrashLoop)'.
#!/bin/bash
POD="your-pod-name"
# Check certificate expiry
kubectl exec -it $POD -c istio-proxy -- \
cat /etc/certs/cert-chain.pem | \
openssl x509 -noout -enddate
# Verify certificate chain
kubectl exec -it $POD -c istio-proxy -- \
openssl verify -CAfile /etc/certs/root-cert.pem \
/etc/certs/cert-chain.pem
# Check SANs in the certificate
kubectl exec -it $POD -c istio-proxy -- \
cat /etc/certs/cert-chain.pem | \
openssl x509 -noout -text | grep -A1 "Subject Alternative"
# Check Envoy's TLS stats for errors
kubectl exec -it $POD -c istio-proxy -- \
curl -s localhost:15000/stats | grep -E 'ssl.*(fail|error)'Start with expiry (most common), then chain validation, then SANs, then key usage. Most issues fall into one of these categories.
Making Rotation Invisible
The goal is automation so complete that certificate rotation becomes invisible — happening continuously in the background without human intervention or service disruption.
mTLS for Service-to-Service Communication
Certificate rotation, trust hierarchies, and the operational footguns that make mTLS harder than it looks.
What you'll get:
- Certificate hierarchy design patterns
- Rotation drill runbook template
- Handshake failure debug workflow
- Expiry monitoring alert pack

Certificate TTLs are a tradeoff. Short-lived certificates (24 hours) limit the damage from a compromised certificate but require robust automation. Longer certificates (7 days) are more forgiving of automation failures but increase your exposure window.
Start with permissive mode, add monitoring before enforcement, and run a rotation drill before you need it for real. Your first rotation drill should happen within 30 days of enabling mTLS — before you’ve forgotten the deployment details and before the first real expiration hits. When your certificates rotate and nobody notices, you’ve built a mature mTLS operation.
Share this article
Enjoyed the read? Share it with your network.




