
Deep Dive
Why Your E2E Tests Are Flaky (And How to Fix Them)
Race conditions and environment issues cause 85% of flaky tests. Here are concrete patterns to diagnose and eliminate both.
Learn more

SLOs, error budgets, incident response, and testing strategies for production health
Reliability engineering is the practice of keeping systems running when everything conspires to make them fail. It spans the technical (circuit breakers, backpressure, retry budgets) and the organizational (incident response, blameless postmortems, on-call rotations that do not burn people out). The goal is not perfection but predictability: understanding how systems fail, measuring what matters, and making informed tradeoffs between availability and velocity.
This category covers both the SRE fundamentals and the testing practices that support them. SLOs sound simple until you try to pick indicators that actually reflect user experience. Error budgets are powerful negotiation tools until leadership treats them as targets instead of tradeoffs. On-call rotations work until you have three people and 200 alerts. E2E tests provide confidence until flakiness erodes trust. These articles dig into the operational reality of reliability work, where the hard part is rarely the technology.
Whether you are introducing SLOs to a team that has never measured availability, trying to reduce alert fatigue without missing real incidents, debugging flaky tests that only fail in CI, or running chaos experiments without an expensive platform, the content here reflects hands-on experience with the unglamorous work of keeping production healthy.
Race conditions and environment issues cause 85% of flaky tests. Here are concrete patterns to diagnose and eliminate both.

A practical three-step framework to audit your alerts, classify them by usefulness, and delete the noise that's hiding real incidents.
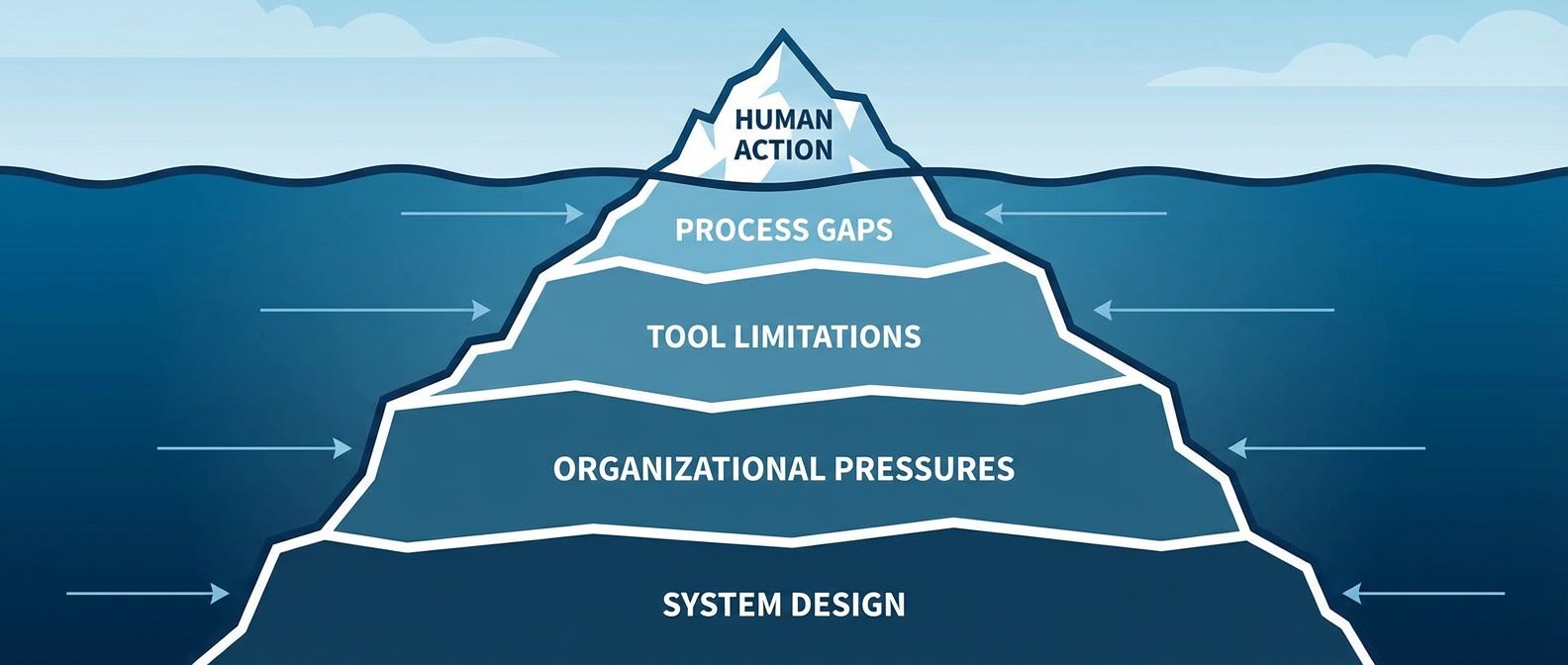
Why blame feels satisfying but fails to prevent recurrence, and how to build incident analysis that finds systemic causes instead of scapegoats.
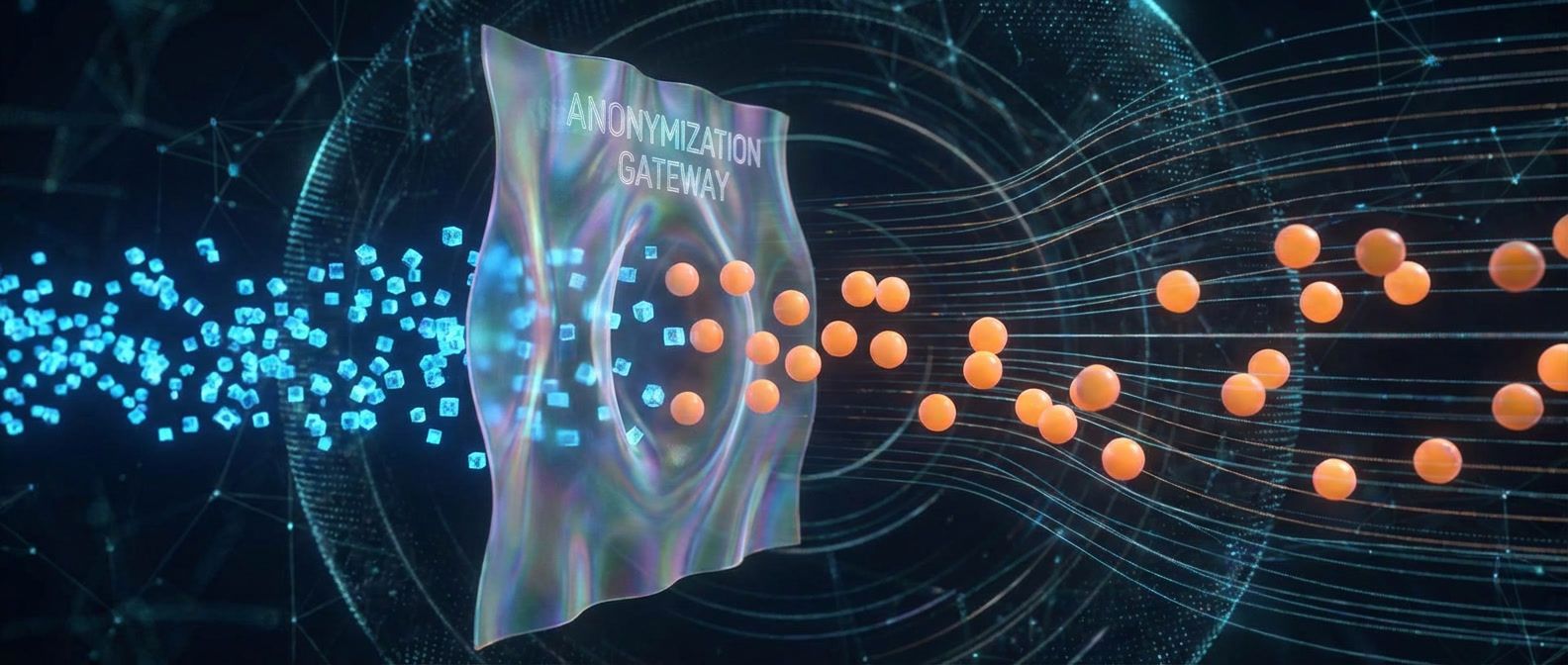
Generate realistic test fixtures without copying production data or risking compliance violations.
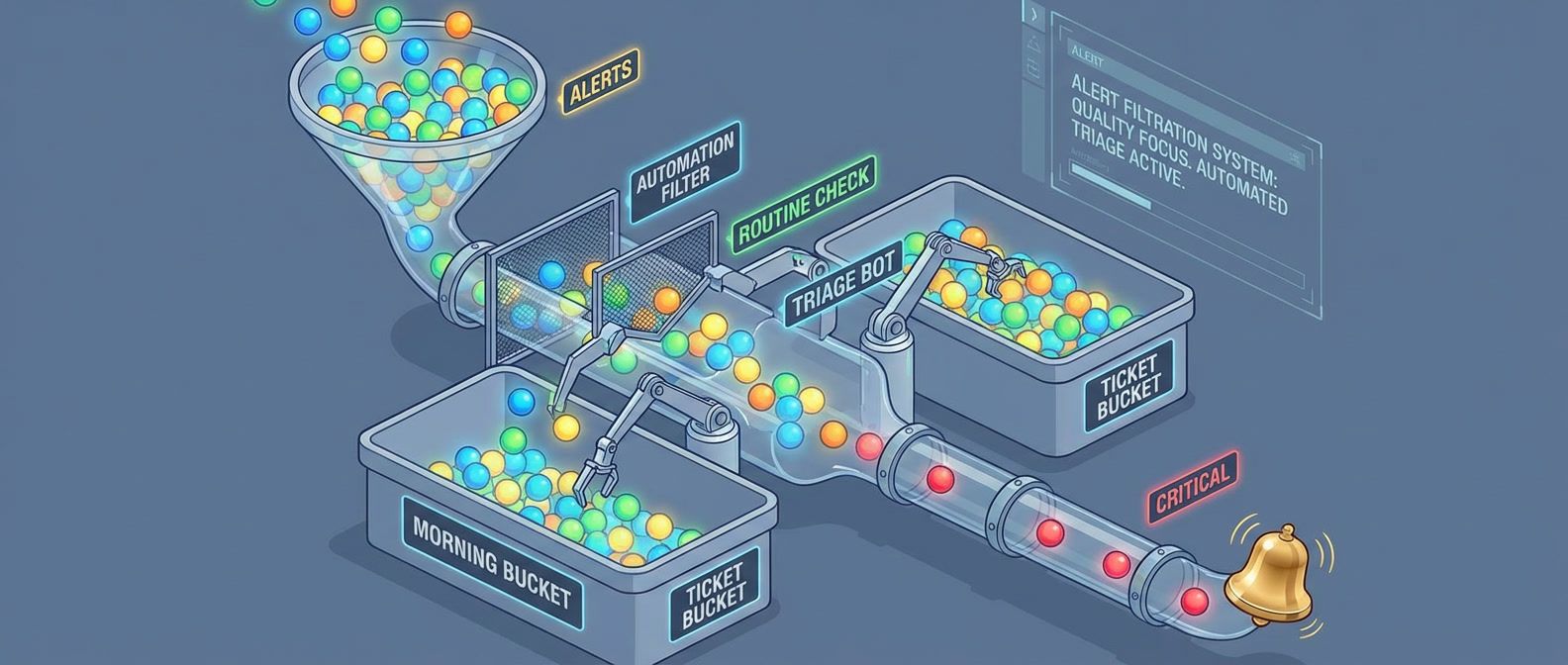
Signal-to-noise ratio determines whether your on-call rotation is sustainable or slowly destroying your team. Here's how to measure it, spot the warning signs, and fix it before someone quits.

The hidden flaws in load testing that produce impressive but meaningless numbers, and how to fix them.
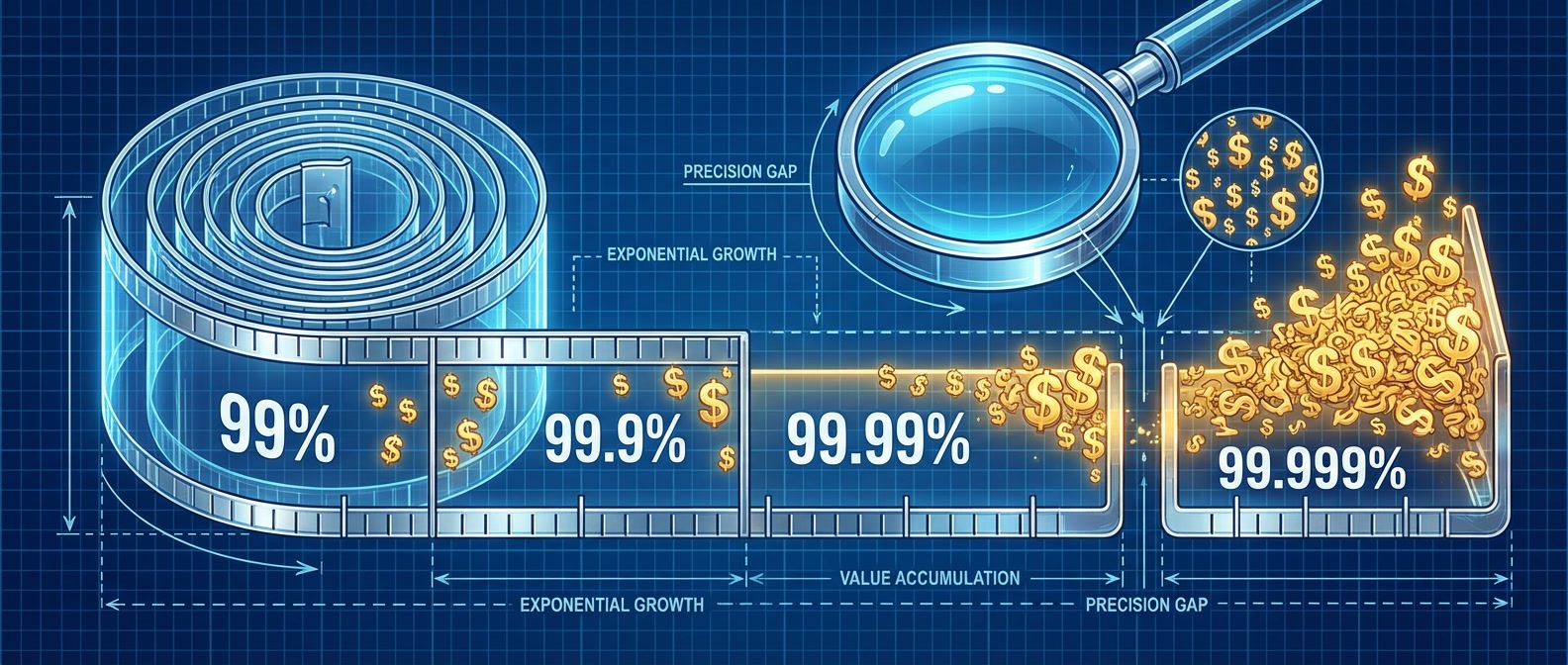
The math that shows why extreme availability targets rarely make business sense — and how to push back when someone asks for them.

The fix isn't better scanners — it's better policies. Configure vulnerability scanning that reports actionable findings instead of overwhelming noise.

Stop debating whether deployments are 'safe enough.' Error budgets convert reliability from an opinion into a number you can spend.

Why systems that try to handle all the load end up handling none of it, and how admission control and load shedding keep services alive under pressure.

Run your first chaos experiment this week with nothing but kubectl and a hypothesis. No expensive platforms required.