Stop Blaming Engineers: Blameless Postmortems Work
Table of Contents
An engineer fat-fingers a production config change. The payment service goes down for two hours. Customers are angry, revenue is lost, and everyone wants to know what happened.
The instinctive investigation goes like this: Who made the change? Why weren’t they more careful? They need more training. Maybe a written warning. Case closed.
This feels satisfying — we found the problem and addressed it. But three months later, a different engineer makes a different config mistake, and we’re back here again. The “solution” didn’t prevent anything — it just rotated the blame to someone new.
There’s a better way.
Why Blame Feels Right But Fails
Blame provides closure. We have a narrative: someone did something wrong, we identified them, and we’ve dealt with it. Our brains crave this kind of simple causation. It’s cognitively easier than grappling with systemic complexity.
But blame produces terrible outcomes. When people fear punishment for mistakes, they stop reporting near-misses. They hedge their language in postmortems. They cover their tracks. The information you need to prevent future incidents disappears into self-protective silence.
| Blame-Based Approach | Systemic Approach |
|---|---|
| Finds a person to hold accountable | Finds system conditions to improve |
| Investigation stops at human action | Investigation continues to context |
| "Don't do that again" | "Make that harder to do" |
| People hide mistakes | People report near-misses |
| Same incident recurs with different person | Incident class becomes less likely |
The divergence compounds over time. Blame-focused organizations accumulate hidden risk because they’ve optimized for concealment. Systems-focused organizations accumulate learning because they’ve optimized for disclosure.
Beyond information hiding, blame-based thinking leads to another trap: the search for a scapegoat. There’s a comforting belief that most engineers are careful and competent, and incidents happen because a few “bad apples” are careless. If we could just identify and remove these people, incidents would stop.
This theory has been tested extensively in aviation, healthcare, and nuclear power. It doesn’t hold up. “Careless” people aren’t a distinct population you can screen out — everyone makes errors under the right conditions. Fatigue, time pressure, confusing interfaces, incomplete information, and conflicting priorities create errors in even the most skilled practitioners.
If you fire the engineer who made today’s mistake, someone else will make a similar mistake next month — because the conditions that enabled the error remain unchanged.
What “Blameless” Actually Means
“Blameless” is frequently misunderstood. It doesn’t mean no one is accountable. It doesn’t mean we ignore mistakes or lower our standards. It means we hold the right things accountable — and in complex systems, that’s almost never an individual human making a one-off error.
| # | What Blameless IS | What Blameless IS NOT |
|---|---|---|
| 1 | Holding systems accountable | Letting individuals off the hook |
| 2 | Safe to report errors | Safe to be negligent |
| 3 | Learning from mistakes | Ignoring mistakes |
| 4 | Improving processes | Accepting poor processes |
| 5 | Psychological safety | Lack of standards |
The distinction matters because different types of accountability call for different responses. An engineer who made an honest mistake while following normal practices needs system improvements. A manager who created deadline pressure that encouraged skipping safety checks needs to change their leadership approach. These are both accountability — just not the “find someone to blame” kind.
The Just Culture framework, developed in healthcare and aviation, helps distinguish between behaviors:
- Human error
- Inadvertent — a typo, a misremembered procedure. The response is system improvement.
- At-risk behavior
- Involves conscious shortcuts where the person doesn't fully appreciate the risk — skipping a checklist because "it's always fine." The response is coaching and removing incentives for the shortcut.
- Reckless behavior
- Conscious disregard of a known substantial risk — genuinely rare in professional settings and the only category where punitive action may be appropriate.
Most incidents involve human error or at-risk behavior. Both call for system-level responses, not individual punishment.
You can’t mandate blameless culture. If people have seen colleagues punished for mistakes, no policy will make them feel safe. Building trust takes consistent behavior over time, especially from leadership.
Finding Contributing Factors, Not “Root Causes”
The phrase “root cause” implies there’s one cause at the bottom of the causal chain — find it, fix it, and the problem is solved. In complex systems, this is almost never true. Incidents arise from the confluence of multiple factors, none of which is the cause. Remove any one of them, and the incident might not have happened — or might have happened differently.
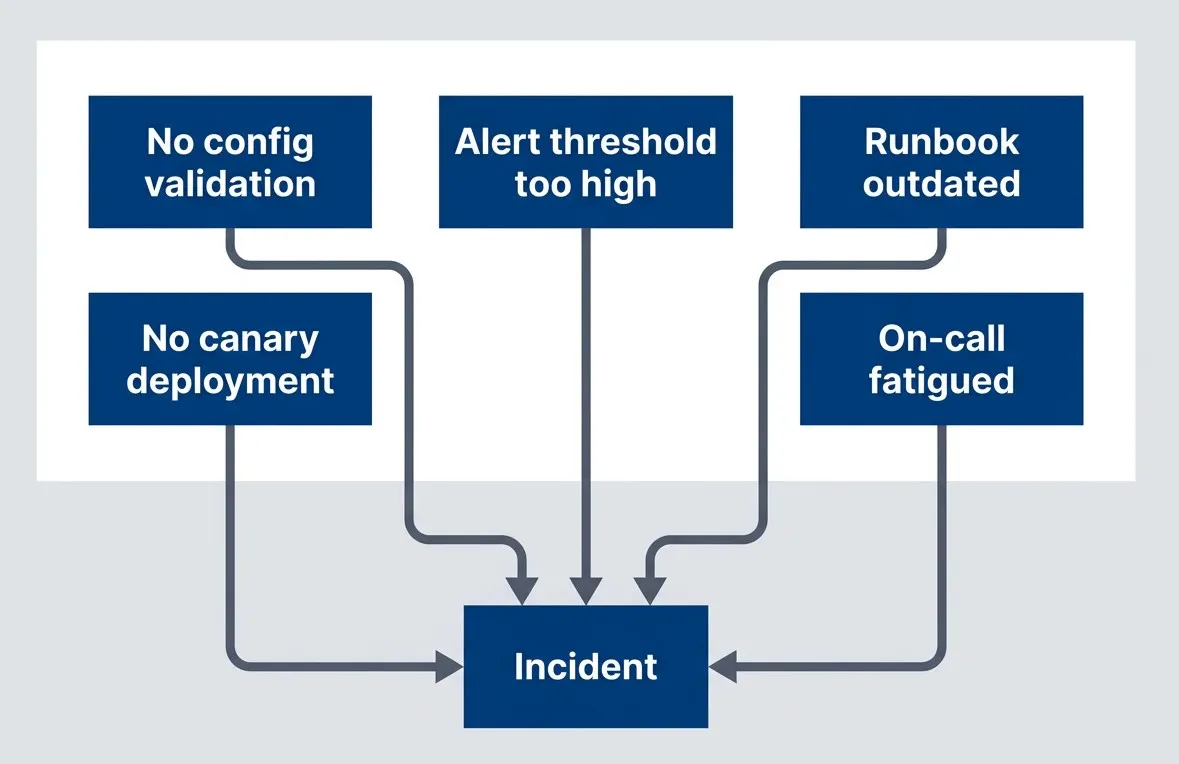
Multiple contributing factors, each representing a potential intervention point
description
Flowchart showing several independent contributing factors converging on a single incident. No config validation, No canary deployment, Alert threshold too high, Runbook outdated, and On-call fatigued each point into Incident. The diagram emphasizes that complex failures typically arise from multiple interacting conditions rather than one root cause, and that each contributing factor is a possible place to intervene and reduce future risk.
The Five Whys technique — keep asking “why” until you reach an actionable cause — is popular but easily misused. Here’s what going wrong looks like:
- Why did the system go down?
- Because a config change broke it.
- Why did the config change break it?
- Because the engineer made a mistake.
- Why did the engineer make a mistake?
- Because they were careless.
Five Whys antipattern that stops at blame — nothing actionable learned.
And here’s the same incident investigated properly:
- Why did the system go down?
- Because a config change disabled authentication.
- Why did the config change disable authentication?
- Because the config schema changed and old values became invalid.
- Why did old values become invalid?
- Because the migration script didn't update existing configs.
- Why didn't the migration update existing configs?
- Because no one knew configs existed in that format.
- Why didn't anyone know?
- Because documentation was outdated and there was no config inventory.
Five Whys done well, leading to systemic improvements from actionable issues.
The difference is where you choose to stop. If you reach a human attribute — careless, rushed, didn’t know — that’s a signal you’ve taken a wrong turn. Human attributes aren’t fixable. But every human attribute has a system context: Why was carelessness possible? What created the rush? Why wasn’t the knowledge available?
Five Whys works when each “why” leads to a system condition. It fails when it leads to human attributes. If you reach “they were careless,” ask instead: “what about the system allowed carelessness to cause an incident?”
Action Items That Actually Prevent Recurrence
The analysis is only as valuable as the actions it produces. I’ve seen beautifully written postmortems with insightful contributing factor analysis — followed by vague action items like “improve monitoring” that never get done and wouldn’t help much if they did.
Good action items share specific characteristics:
| Characteristic | What It Means | Example |
|---|---|---|
| Specific | Describes the exact change, not the general area | "Add validation for auth config changes" |
| Measurable | Has a clear done/not-done state you can verify | "Deploy canary to 1% before full rollout" |
| Assignable | Names a team and person, not "we" or "someone" | "Platform team owns, Sarah implements" |
| Realistic | Scoped to complete in the committed timeframe | "Can be completed in one sprint" |
| Systemic | Blocks the failure mode, not just this instance | "Blocks all invalid configs, not just this format" |
Those characteristics sound straightforward in the abstract, but the difference shows up quickly when you compare action items side by side. One set points to concrete engineering changes you can implement and verify; the other just restates frustration in softer language.
- Good examples:
- "Add pre-deploy hook that validates config schema." "Implement 1% canary with automatic rollback on error spike." "Add config change review requirement to deploy pipeline."
- Bad examples:
- "Be more careful with config changes." "Engineer X needs training." "Review all configs." "Improve monitoring."
The “bad” examples are common because they’re easy to write. But “be more careful” changes nothing structural and relies on human vigilance — exactly what failed. “Engineer X needs training” is blame dressed up as remediation. “Review all configs” and “improve monitoring” lack the specificity needed to actually get done.
An incident without completed action items is an incident that will recur. Track actions to completion, verify they work, and close the loop in a follow-up meeting.
Here’s a useful test: if someone else picked up the action item, would they know exactly what to build or change? If the answer is no, refine it until they would.
The Path Forward
Blameless postmortems aren’t soft — they’re more rigorous than blame culture. They demand that we find all the contributing factors, not just the most obvious one. They demand real fixes, not just “be more careful.” They demand measurement to verify fixes actually work.
Download the Blameless Postmortem Guide
Get the complete incident analysis playbook for systemic investigations, facilitator workflows, and recurrence-prevention action tracking.
What you'll get:
- Systemic cause analysis templates
- Facilitator interview language guide
- Postmortem action tracking framework
- Psychological safety implementation playbook

The core principles:
- Human error is where investigation begins, not where it ends — the interesting question is always: what made that action likely, possible, and undetected?
- Blame produces hiding; systems thinking produces learning — when people fear punishment, they stop reporting. When they feel safe, they share near-misses that prevent future incidents.
- Incidents have contributing factors, not root causes — complex failures arise from multiple interacting conditions. Identify them all before deciding which to fix.
- Effective remediation requires specific, systemic action items tracked to completion — vague actions don't get done. Person-focused actions don't prevent recurrence.
The organizations that learn fastest are the ones where people feel safe enough to say “I made a mistake, and here’s what we should change so it doesn’t happen again.”
The next time an engineer fat-fingers a config change, your organization has a choice: find someone to blame, or find five ways to make sure it can’t happen again. Only one of those prevents the next incident.
Share this article
Enjoyed the read? Share it with your network.




