
Deep Dive
Your Rate Limiter Is Your Biggest Outage Risk
Why your rate limiter might be your biggest outage risk — and how to fix it with the right algorithms and architecture.
Learn more

Multi-cloud infrastructure-as-code with HCL, state management, and module reuse
Terraform is the most widely adopted infrastructure-as-code tool in platform engineering. Its declarative HCL syntax, plan-and-apply workflow, and provider ecosystem covering every major cloud and SaaS platform give teams a consistent way to define, version, and provision infrastructure regardless of where it runs. The state file acts as a source of truth that tracks what exists, what changed, and what needs to be created or destroyed on the next apply.
Platform teams build on Terraform by composing reusable modules that encode organizational standards. A VPC module enforces network segmentation policies, a Kubernetes cluster module wires up node pools with the right instance types and autoscaling rules, and a database module handles encryption, backup schedules, and parameter groups. Published to private registries and consumed through version-pinned module calls, these become the building blocks of self-service infrastructure that application teams request without writing HCL themselves.
The operational challenges are state management and drift. Remote state backends, state locking, and workspace isolation prevent concurrent modifications from corrupting infrastructure, but they add coordination overhead. Large monolithic state files slow plan times and increase blast radius. Teams that invest in state decomposition, automated drift detection, and policy-as-code with Sentinel or OPA build Terraform workflows that scale across hundreds of engineers and thousands of resources.
Why your rate limiter might be your biggest outage risk — and how to fix it with the right algorithms and architecture.

Design module interfaces with sensible defaults, clear breaking-change boundaries, and early validation to create modules teams actually want to use.

A data-driven framework for identifying which dashboards to keep, archive, or delete — and how to make cleanup stick.

Lead time, onboarding time, and ticket deflection metrics that show whether your platform reduces friction.
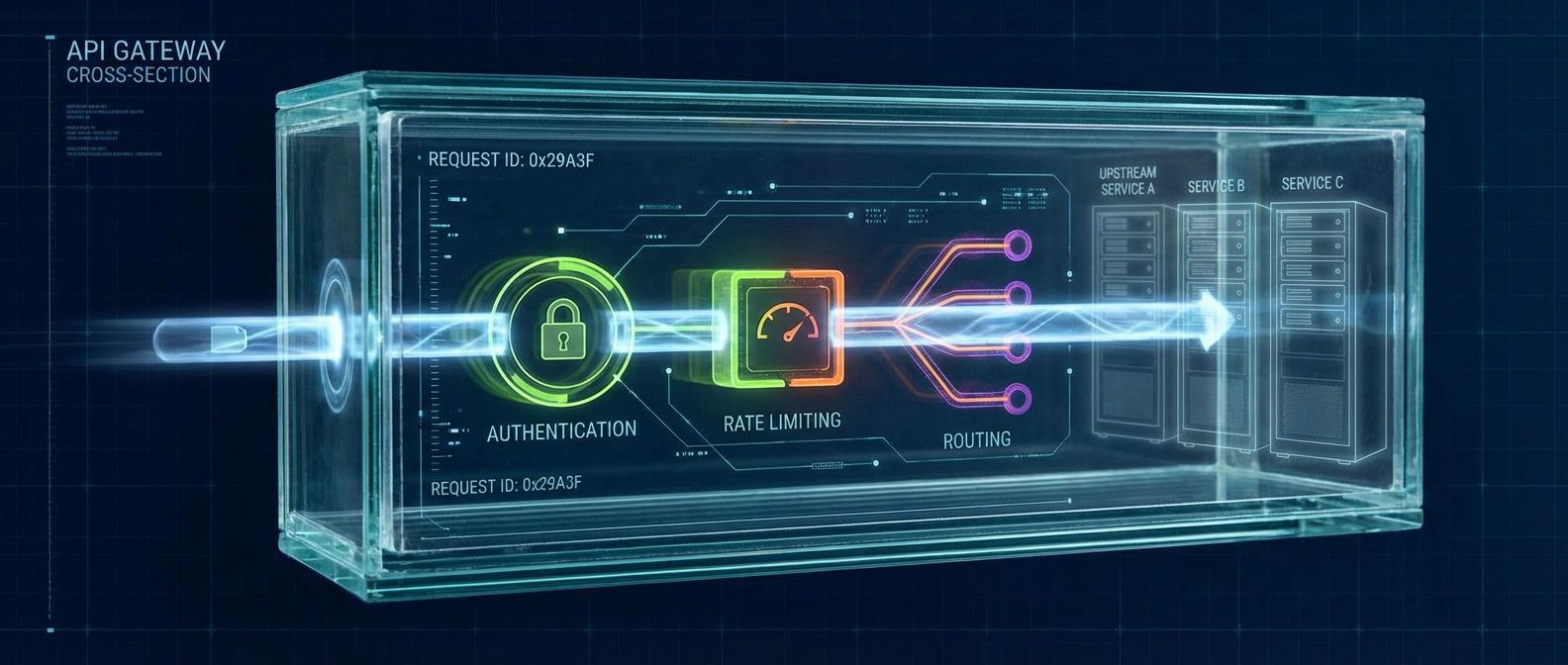
Your gateway dashboards show healthy 200ms latency, but users report 5-second delays. The problem isn't the gateway — it's what you're measuring.
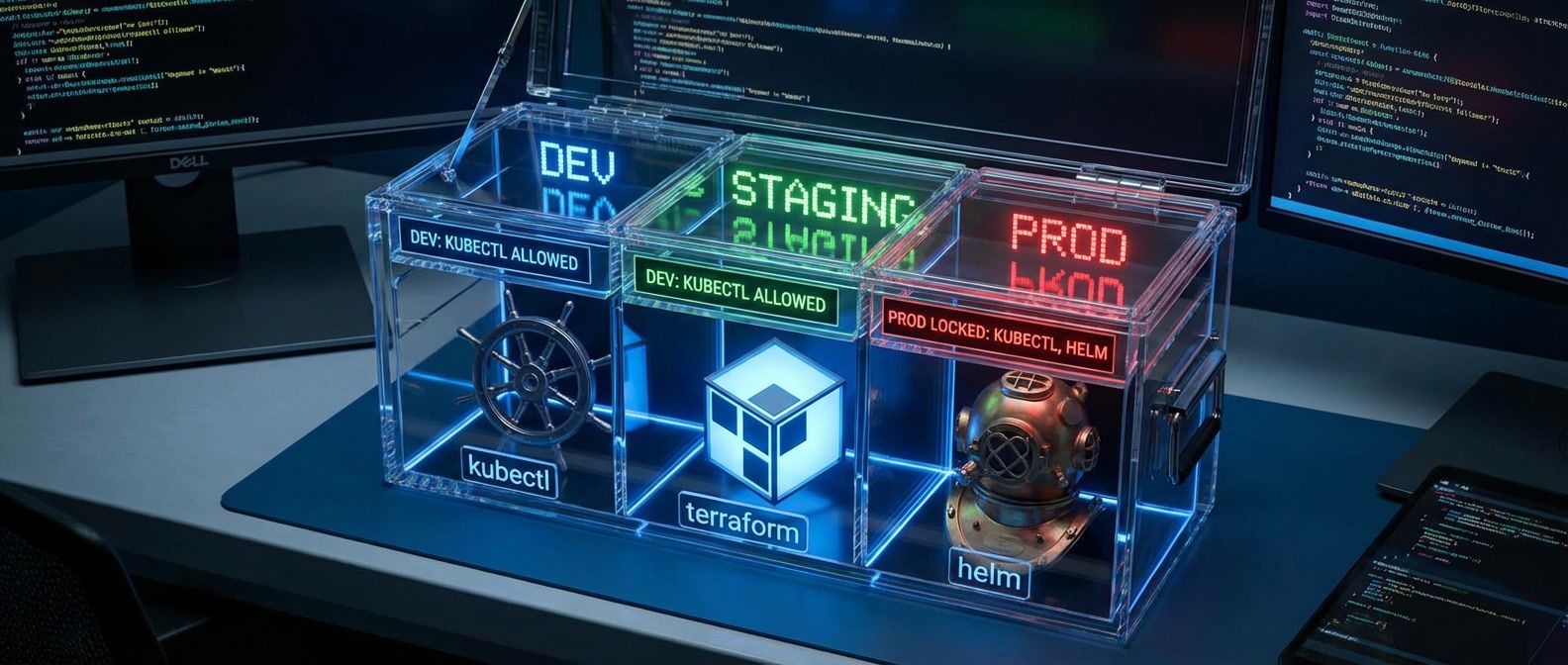
When to build abstractions over kubectl or terraform and when the wrapper creates more problems than it solves.

Long-lived service account keys are the most common - and most preventable - cloud security vulnerability. Workload identity federation replaces static credentials with cryptographic proof of identity, eliminating an entire category of risk.

Implementing infrastructure policies with OPA and Conftest that catch violations before they reach production — starting with pre-commit hooks that run in under two seconds.

Recognize state corruption symptoms and apply the right recovery procedure: force-unlock for stuck locks, import for orphaned resources, backup restoration for severe corruption.

Separating platform control surfaces from runtime infrastructure for multi-team boundaries and scaling.

The difference between a portal that indexes things and a platform that does things for developers.